Синхронизация публикаций - в помощь сетератору. Работа со списками в Excel.
 Предлагаю авторам, испытывающим необходимость отслеживать свои публикации на разных порталах, таблицу, собственноручно свёрстанную в Excel. Она изначально создана именно для этой цели, но может пригодиться и не по прямому назначению. Например, для сравнения списка учеников в классе этого года с прошлым или своей видеоколлекции со списком друга.
Предлагаю авторам, испытывающим необходимость отслеживать свои публикации на разных порталах, таблицу, собственноручно свёрстанную в Excel. Она изначально создана именно для этой цели, но может пригодиться и не по прямому назначению. Например, для сравнения списка учеников в классе этого года с прошлым или своей видеоколлекции со списком друга.
|
Первые два пункта и последний, думаю, понятны и без пояснений, а вот если вы не желаете копаться в формулах, логике их работы, просто не нужны подробности создания таблицы, то третий пункт можете пропустить. Скачайте архив, ознакомьтесь с инструкцией к применению и пользуйтесь готовым файлом, модернизировав под свои нужды, попросту заменив списки на свои, и переименовав заголовки.
Зачем я это сделал?
Мой сетевой стаж (на момент написания этой статьи) три с половиной года, за это время накопилось около сотни произведений, в разной степени активен на пяти Литсайтах, на некоторых просто ради конкурсов, другие страницы содержатся как резервные. Логика такова - чем больше у меня страниц, тем проще доказать авторские права, плюс любой портал временами лихорадит, потому лучше иметь страховку. Но вернёмся к теме. На эти пять порталов публикации добавлялись бессистемно. Т.е. в определённый момент возникла необходимость отслеживать наличие публикаций на той или иной веб странице. Вести статистику вручную мне всё как-то не давалось. То забуду пометить то, что добавил, то просто не хватало времени, а потом приходилось заново отслеживать вручную накопившиеся изменения. Тогда и родилась идея создать таблицу, которая автоматически анализировала бы списки публикаций и указывала каких, и на каком сайте не хватает.
Как это работает?
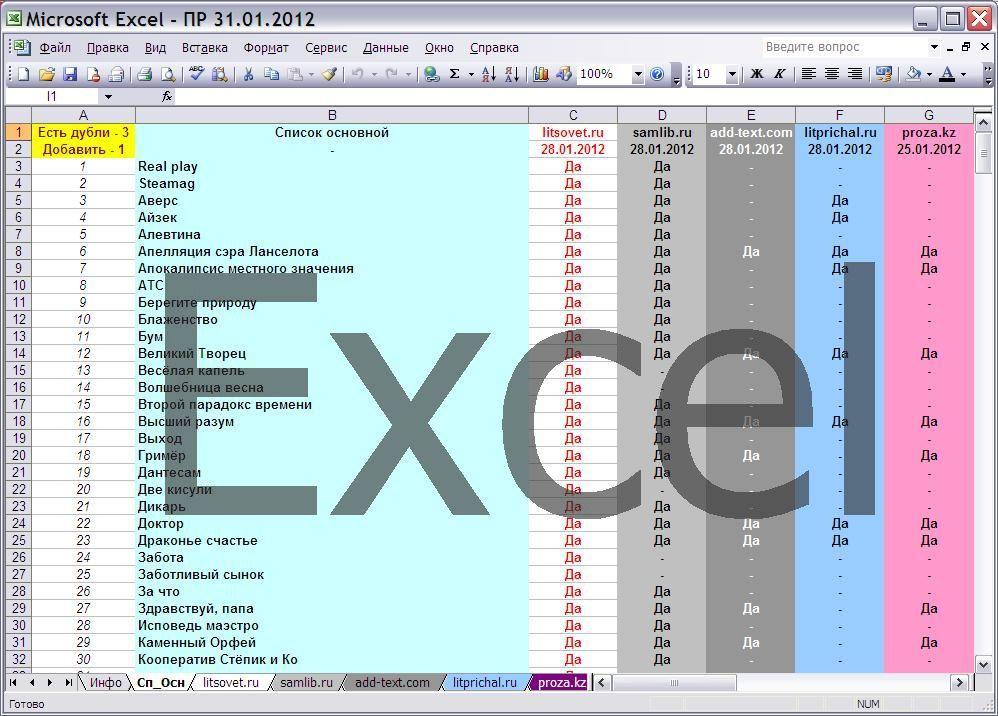
В Excel файле создано шесть листов (не считая Инфо). Сп_Осн (Список Основной) является "корневым" и наиболее полным списком моих произведений, формируется постепенно, может дополняться, так же можно произвести сортировку, т.к. порядок публикаций в списке не повлияет на конечный результат. В нём и происходит сведение всех данных.
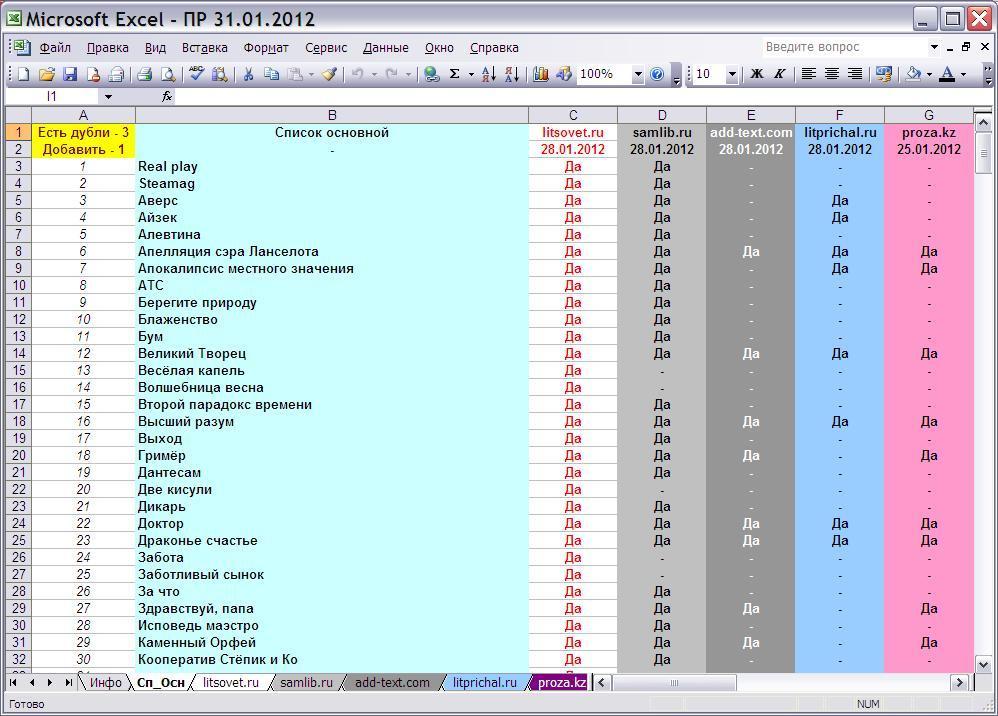
Остальные листы - каждый соответствует одному порталу, содержит список произведений на нём (портируется вручную)
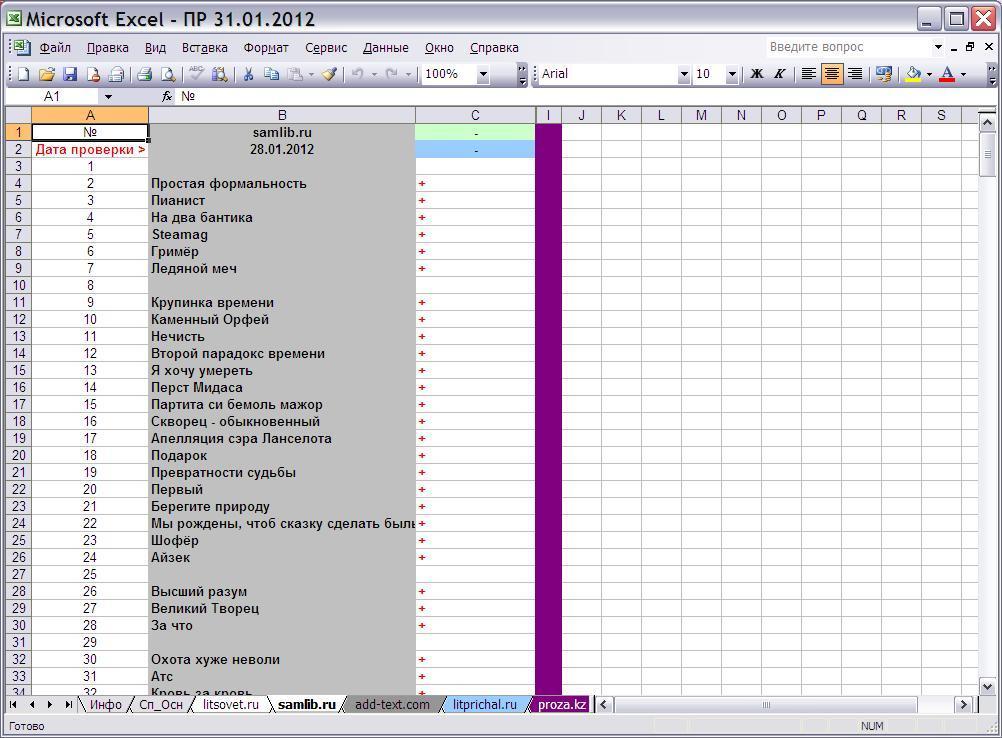
Каждый содержит формулы вычислений (столбцы с последними скрыты, чтобы не "рябило в глазах", только в листе proza.kz они намеренно оставлены видимыми, для наглядности).
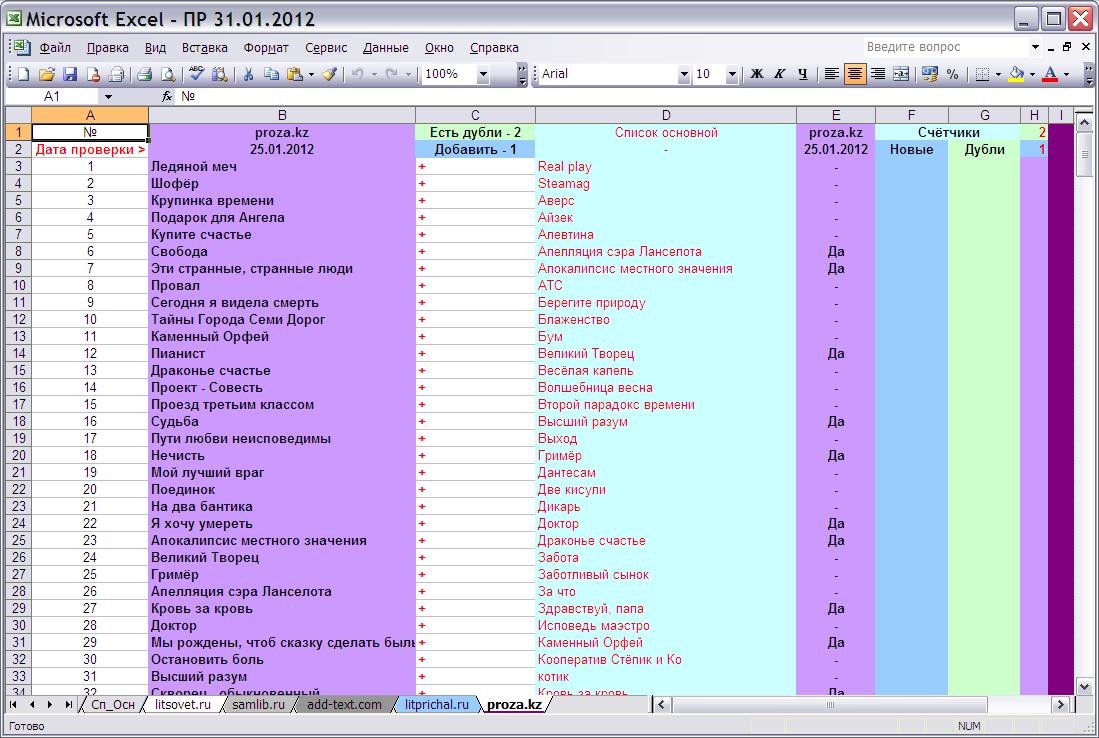
Формулы содержатся в столбцах С, E, F, G, H, они нужны для отображения конечного результата на листе Сп_Осн, а в D, копия "корневого списка" лишь для наглядности, в остальных листах D пуст. Количество столбцов и формул сокращено по сравнению с предыдущим вариантом таблицы (фото ниже), вам представлена редакция версии 1.1 и вероятно не конечная.
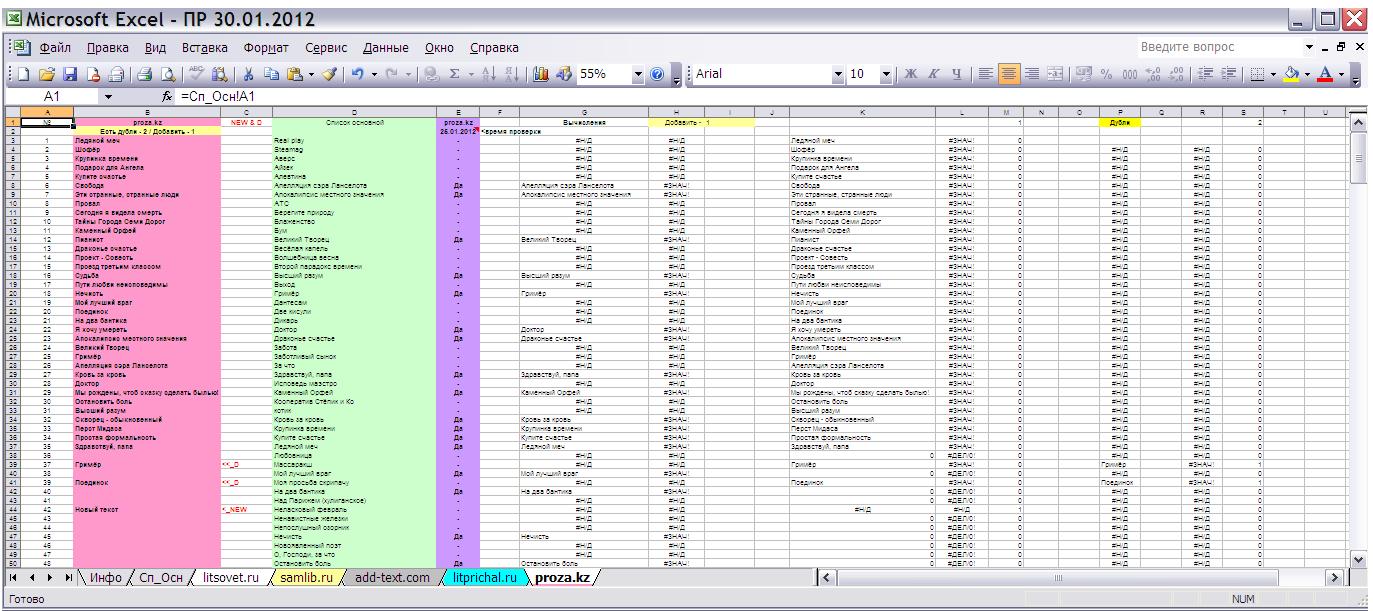
В столбце C реализован поиск дублей (одинаковых названий) в "дочерних" списках и поиск новинок, произведений, ещё не внесённых в основной список. Если произведение повтором не является и есть в основном списке, то помечается плюсом. Счётчики запрятаны в F, G и H, а в ячейках C1 и C2 они уже отображаются с комментариями.

В столбце E задаётся правило, при котором "список портала" сравнивается с основным списком, и в "корневом" листе (Сп_Осн) в соответствующем столбце отображается "Да" если произведение опубликовано на сайте, или короткое тире "-", чтобы ячейка выглядела пустой, но таковой не являлась в знак подтверждения работы "анализатора".
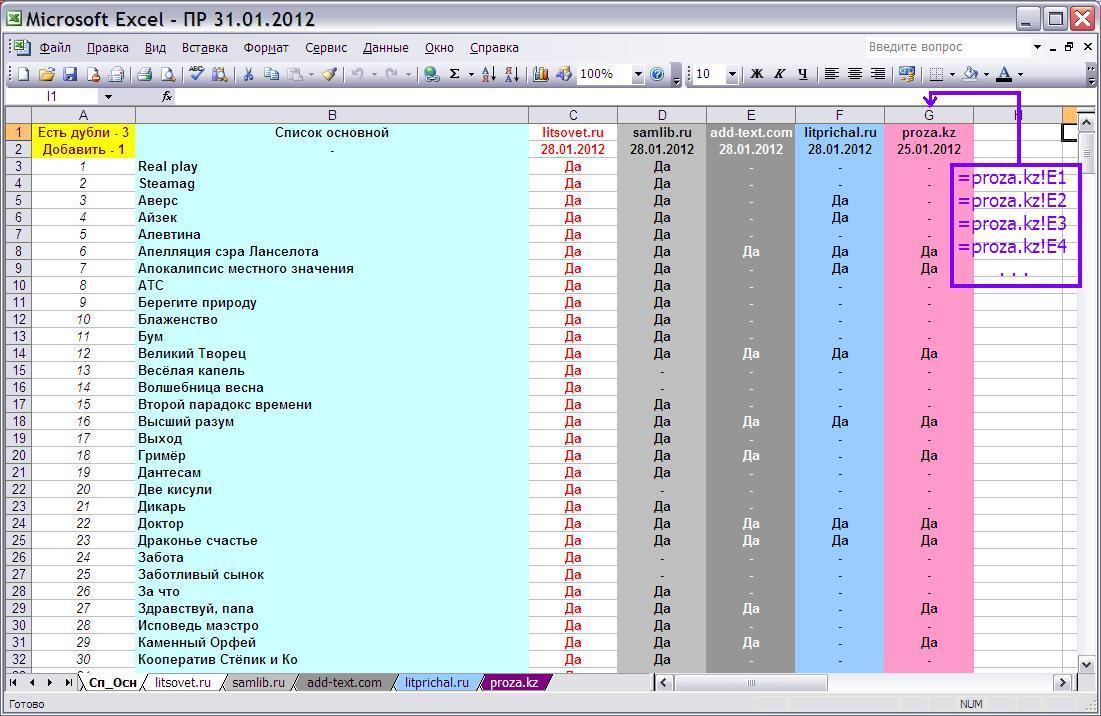
Т.е. в Сп_Осн полностью копируется столбцы E из всех остальных листов.
Как я это сделал?
►► пропустить раздел
Открыл новый файл Excel и начал эксперименты. Функции ЕСЛИ явно не хватало, на ней одной вышло бы слишком громоздко, если вообще получилось. Стал просматривать другие функции из списка, выбрав в панели инструментов, Вставка - Функция. В появившейся панели кроме группировки по категориям я с восторгом обнаружил окно Поиск функции. По ключевому слову "Поиск" и нашлась функция ВПР. Как гласит описание - Ищет значение в крайнем левом столбце таблицы и возвращает значение в той же строке из указанного столбца таблицы. После экспериментов с ней оказалось, что это то, что нужно.
схема формулы:
ВПР(искомое_значение;таблица ;номер_столбца ;интервальный_просмотр)
"интервальный_просмотр" я выбрал "ЛОЖЬ", т.к. только в этом случае сортировка обрабатываемого списка не требуется.
Так выглядит часть кода для поиска совпадений и отображения одинаковых значений в обоих списках с сортировкой в порядке основного списка.
=ВПР(Сп_Осн!B:B;B:B;1;ЛОЖЬ)
=ВПР(Сп_Осн!B:B;B:B;1;ЛОЖЬ)
=ВПР(Сп_Осн!B:B;B:B;1;ЛОЖЬ)...
Т.е. берётся текущая ячейка из "Основного списка" (столбец B) и осуществляется поиск по всему списку в столбце B. Если значение есть в обоих списках, то оно отображается в текущей ячейке, в которой находится формула.
Важно - поиск ведётся по полному совпадению, поэтому необходимо единообразное написание.
Но если значение не найдено, то отображается код ошибки #Н/Д. Эта ошибка и стала камнем преткновения. Перевести название произведения в слово "Да", а #Н/Д, в тире оказалось сложной задачей. Чтобы я не придумывал, #Н/Д упрямо не хотело становиться значением, с которым можно было бы работать дальше. Собственно, можно было бы оставить всё как есть, и ограничиться одной этой формулой, но воспринимать информацию в таком виде неудобно - названия могут быть длинными, а от #Н/Д "рябит".
Поиск функции, которая бы превращала ошибку в другое значение привёл меня к функции ТИП.ОШИБКИ, она трансформирует ошибку в число, которому соответствует её код. Поэкспериментировав немного, я выяснил, что и в каскаде формул отображается первая ошибка, она имеет приоритет, даже если были ещё. Это и было моей проблемой во время попытки создать правило трансформации #Н/Д в тире. С той же проблемой я столкнулся применив одиночную формулу ТИП.ОШИБКИ - #Н/Д превращалось в число 7, но названия в списке через эту формулу вызывали новую ошибку ЗНАЧ!. Получился замкнутый круг - ошибка превращалась в число, а данные в ошибку, и все последующие шаги лишь давали их чередование.
И вот тут у меня возникла (пардон за бахвальство) гениальная идея - искусственно симулировать ошибку для найденного значения (имени). Зная, что приоритетна первая ошибка, я превратил этот недостаток в достоинство. Я поделил на ноль результат, полученный формулой ВПР. Таким образом добился двух ошибок - если значение не найдено #Н/Д, если есть название произведения, то отображается ошибка ЗНАЧ! Эти две ошибки преобразуются через функцию ТИП.ОШИБКИ в цифры 7 и 3, а затем в "Да" и "-". Я сэкономил пространство и объединил все функции в столбце E.
Вот "формула успеха"!:
=ЕСЛИ(ЕПУСТО(Сп_Осн!B:B);"";ЕСЛИ(ТИП.ОШИБКИ(ВПР(Сп_Осн!B:B;B:B;1;ЛОЖЬ)/0)=7;"-";"Да"))
Причём =ЕСЛИ(ЕПУСТО(Сп_Осн!B:B);""; потребовалось чисто из эстетических соображений, чтобы отображалось пустое поле вместо тире в ячейках, в местах, где основной список пуст.
Это конечный результат моих мытарств, длившихся три вечера подряд. Точнее ко второму я уже доводил таблицу до ума и добавил функцию поиска дублей и новинок, используя всё те же ВПР, ТИП.ОШИБКИ, деление на ноль и ЕСЛИ с "сотоварищами".
Логика практически та же, правда, формула вышла несколько сложнее. Вот пример из ячейки C5:
=ЕСЛИ(ЕПУСТО(B:B);"";ЕСЛИ(ТИП.ОШИБКИ(ВПР(B5;B$3:B4;1;ЛОЖЬ)/0)=3;"";ЕСЛИ(ТИП.ОШИБКИ(ВПР(B:B;Сп_Осн!B:B;1;ЛОЖЬ)/0)=7;"";"")))
ВПР(B:B;Сп_Осн!B:B;1;ЛОЖЬ) отвечает за поиск новинок, теперь уже значения из "Дочернего списка" сравнивается с "Основным", и если значение не будет найдено, то появится код ошибки, который через ЕСЛИ(ТИП.ОШИБКИ(ВПР_#Н/Д)/0)=7; преобразуется в информацию <_NEW в столбце C.
ВПР(B5;B$3:B4;1;ЛОЖЬ) отлавливает дубли, а
ЕСЛИ(ТИП.ОШИБКИ(ВПР_ЗНАЧ!)/0)=3;
аналогично преобразует код ошибки в <<_D в столбце C, причём приоритетность у значения выше чем у <_NEW , т.е. если новый текст будет повторятся отобразится значение дубля. Плюс отображается если значение из дочернего списка (столбец B) не является новым или повтором.
Формула поиска дублей далась немного сложнее остальных. Сначала я нагородил "многоэтажную" и даже занял несколько столбцов для этого. Но всё оказалось гораздо проще.
=ВПР(B3;B$1:B2;1;ЛОЖЬ)
=ВПР(B4;B$1:B3;1;ЛОЖЬ)
=ВПР(B5;B$1:B4;1;ЛОЖЬ)
=ВПР(B6;B$1:B5;1;ЛОЖЬ)
=ВПР(B7;B$1:B6;1;ЛОЖЬ)...
Алгоритм работы: Значение из текущей строки столбца B сравнивается со всеми предыдущими, начиная с B1, т.е. формула из ячейки C6 сравнивает значение в B6 просматривая интервал от B1 до B5. Запись B$1 запрещает Excel модифицировать это значение при копировании формулы в следующие строки. Ячейка B1 это название портала, а B2 дата проверки, но ничего страшного, вероятность совпадения с названием мало, зато формула всех ячеек приведена к единому стандарту.
Важно - все листы (кроме Сп_Осн) защищены от модификации, чтобы случайно не удалить нужные формулы, к редактированию доступен столбец B:
В первую ячейку вводится заголовок списка, а во вторую дата проверки, далее сам список.
Если требуется модификация таблицы под свои нужды и уверены в своих силах, то пароль на снятие защиты 0000 (Панель инструментов - Сервис - Защита - Снять защиту листа).
В данный момент прописано двести строк до 202-й включительно. Если потребуется больше, просто выделите любую строку между 202-й и 3-й, скопируйте и вставьте, выделив, нужное количество строк ниже.
В первую ячейку вводится заголовок списка, а во вторую дата проверки, далее сам список.
Если требуется модификация таблицы под свои нужды и уверены в своих силах, то пароль на снятие защиты 0000 (Панель инструментов - Сервис - Защита - Снять защиту листа).
В данный момент прописано двести строк до 202-й включительно. Если потребуется больше, просто выделите любую строку между 202-й и 3-й, скопируйте и вставьте, выделив, нужное количество строк ниже.
Ну, и осталась "косметика":
В H1 и H2 прописаны счётчики, которые дублируются в C1 и C2 уже с текстовыми пояснениями, а считают они столбцы F и G, в которых отображается единичка при наличии дублей или новинок, т.е. ссылаются на столбец C.
На H1 и H2 ссылаются счётчики в "корневом" списке, они уже подсчитывают общее количество дублей и новинок во всех "дочерних" списках. Собственно это почти всё. Если требуется большее количество листов, то просто копируется и переименовывается один из "дочерних", затем останется лишь подредактировать в "корневом" счётчики и добавить новый столбец.
Как этим пользоваться?
Почти каждый литпортал предоставляет список произведений, чаще он на авторской странице, но копирование может быть затруднено наличием лишней информации, такой как жанр, аннотации, и т.п., а иногда список разделён на несколько страниц. Проблему можно решить, перейдя в папку статистика (если сервис позволяет), так на сайте Литсовет и Самоиздат списки в статистике предоставлены в табличном виде. Можно выделить всё и потом удалить лишние цифры в промежуточном текстовом документе. Т.е. прежде чем добавить список в Excel требуется предварительная подготовка.
Важно - всегда копируйте списки в Excel через текстовый документ. Промежуточное сохранение в обычном блокноте, удаляет исходное форматирование и лишние объекты, к примеру - картинки, значки, смайлики и т.п. Это гарантия, что не будут задеты соседние столбцы с формулами и всё скопируется правильно. Если копирование было произведено из Word таблицы, то следует удалить лишние табуляторы. Подробней как это делать я опишу в статье "Работа со списками и таблицами в Microsoft Word".
Вставляем полученный с сайта список в лист файла Excel, соответствующий нужному нам порталу (в столбец B). В первую ячейку вводится заголовок списка, а во вторую дата проверки, далее сам список. Если требуется, переименовываем или создаём путём копирования новый лист. Для это кликаем на ярлыке листа правой кнопкой мыши и выбираем Переместить/скопировать и ставим галочку создать копию, так же выбираем место перед каким листом он должен находится.
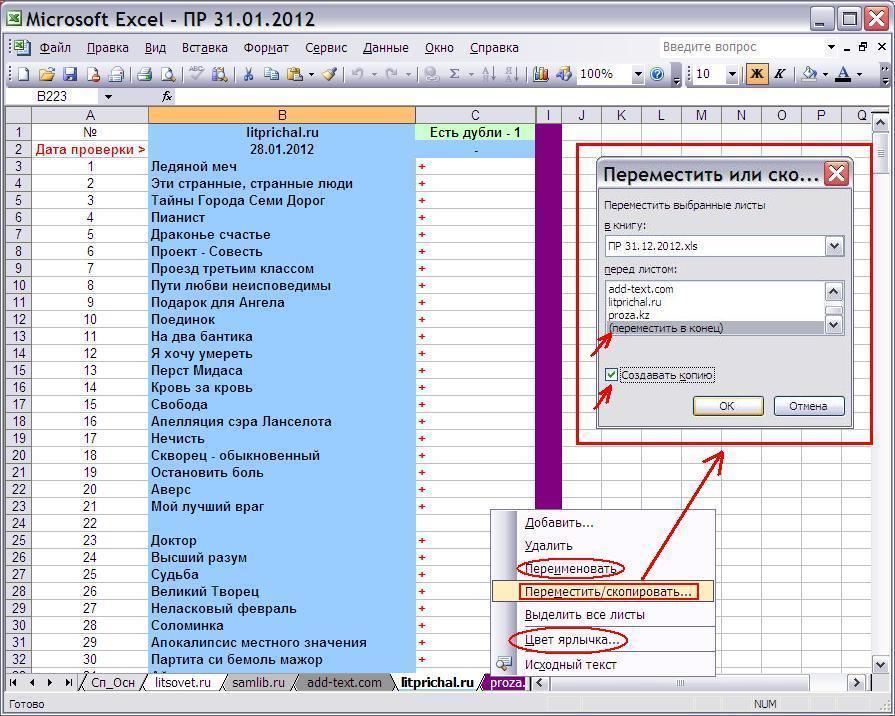
Если осуществили копирование (не забудьте переименовать скопированный лист и сменить цвет ярлычка), то в листе Сп_Осн следует создать очередной столбец (можно назначить ему определённый цвет), в котором следует прописать в первой ячейке ссылку на E1 нового листа и методом копирования заполнить ею весь столбец.
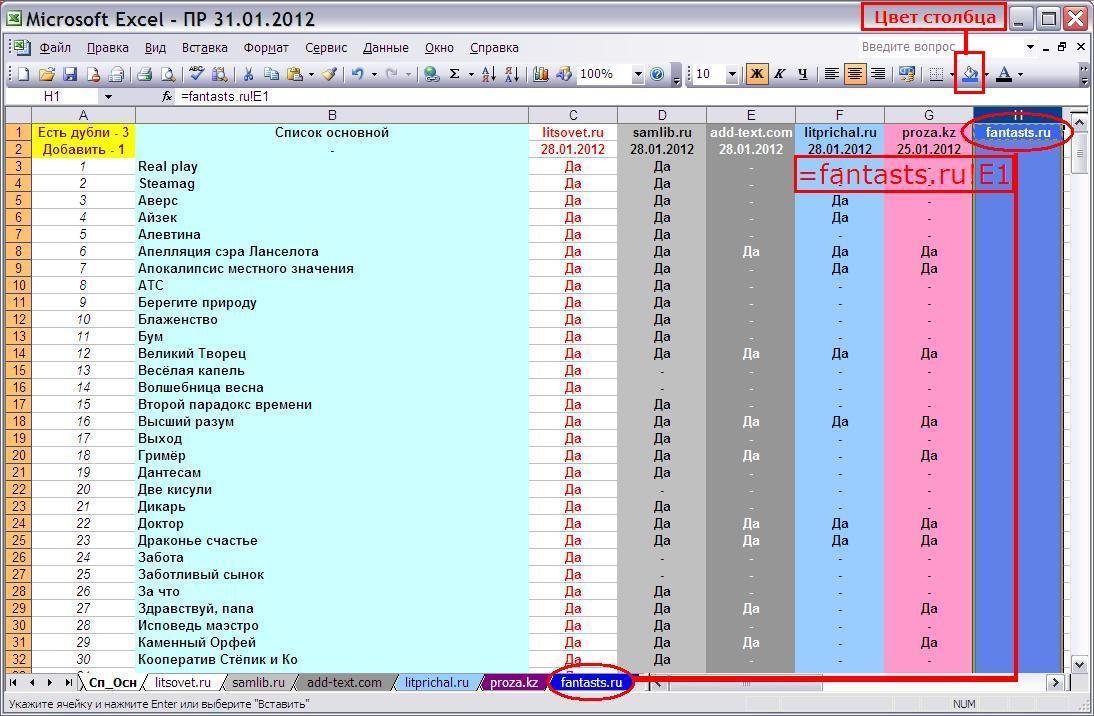
Если при этом дата будет отображаться некорректно, то, выделив вторую ячейку, или целую строку кликом правой кнопки мыши вызываем меню Формат ячеек и в первой вкладке Число устанавливаем Дата.
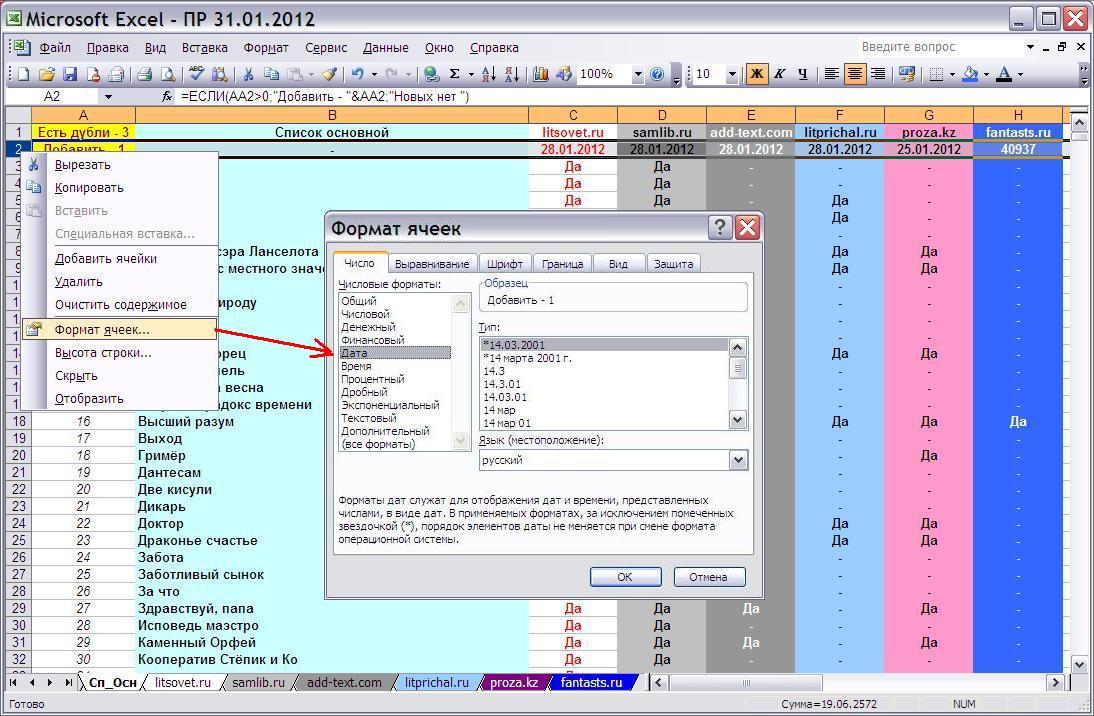
Затем необходимо поправить счётчики в ячейках AA1 и AA2, добавив в формулы счёта ссылки на ячейки H1 и H2 нового листа:
=СУММ(litsovet.ru!H1;samlib.ru!H1;'add-text.com'!H1;litprichal.ru!H1;proza.kz!H1;H1)
Достаточно отредактировать только один счётчик, а потом выделить ячейку, кликнуть копировать и вставить в AA2 (клавиши Ctrl C и Ctrl V), чтобы получить вторую формулу автоматически (для того они один под другим и размещены):
=СУММ(litsovet.ru!H2;samlib.ru!H2;'add-text.com'!H2;litprichal.ru!H2;proza.kz!H2;H1)
Так же можно выделить первые ячейки в Сп_Осн с названиями списков, скопировать их в блокнот, а потом автозаменой (клавиши Ctrl H) преобразовать табуляторы в !H1; и подставить в конец получившейся строки !H1), а в начале =СУММ(.
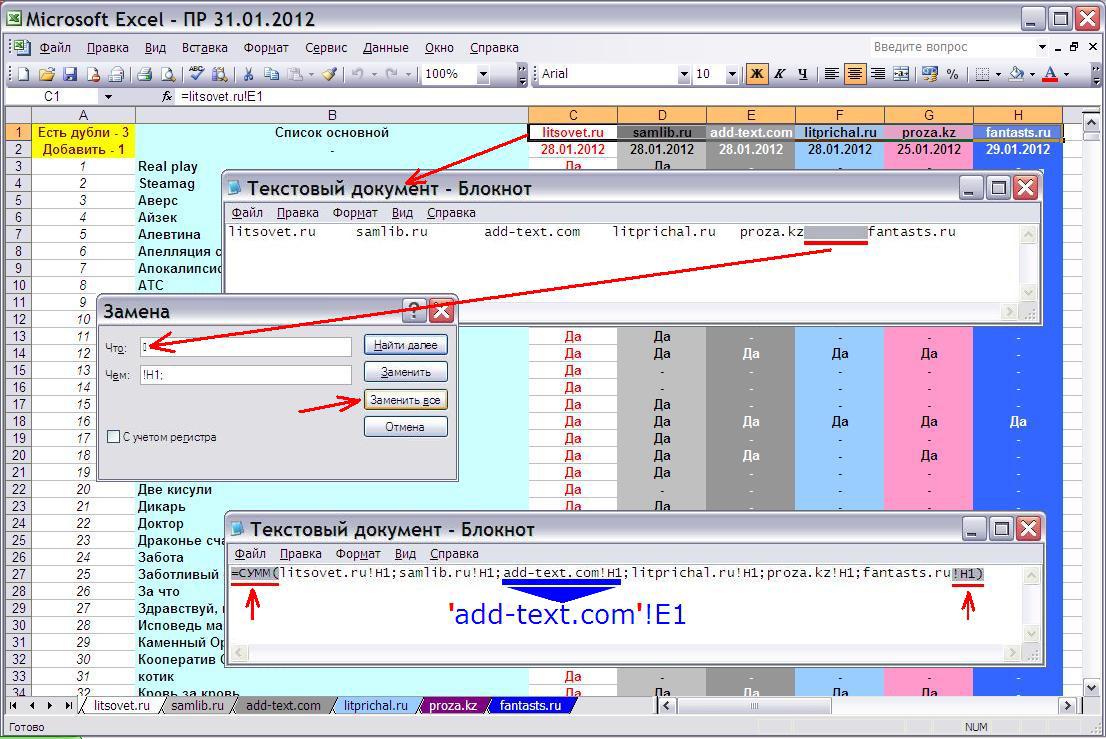
Обратите внимание на запись 'add-text.com'!H1, из-за тире, которое Excel понимает как минус, название заключено в одинарные кавычки, если будете редактировать формулу счётчика вручную, то лучше не использовать в названиях листов математических знаков, иначе можете долго биться над ошибкой, упустив из виду эти кавычки.
=СУММ(litsovet.ru!H1;samlib.ru!H1;'add-text.com'!H1;litprichal.ru!H1;proza.kz!H1;H1)
Достаточно отредактировать только один счётчик, а потом выделить ячейку, кликнуть копировать и вставить в AA2 (клавиши Ctrl C и Ctrl V), чтобы получить вторую формулу автоматически (для того они один под другим и размещены):
=СУММ(litsovet.ru!H2;samlib.ru!H2;'add-text.com'!H2;litprichal.ru!H2;proza.kz!H2;H1)
Так же можно выделить первые ячейки в Сп_Осн с названиями списков, скопировать их в блокнот, а потом автозаменой (клавиши Ctrl H) преобразовать табуляторы в !H1; и подставить в конец получившейся строки !H1), а в начале =СУММ(.
Обратите внимание на запись 'add-text.com'!H1, из-за тире, которое Excel понимает как минус, название заключено в одинарные кавычки, если будете редактировать формулу счётчика вручную, то лучше не использовать в названиях листов математических знаков, иначе можете долго биться над ошибкой, упустив из виду эти кавычки.
Основной список полезно сформировать из списка с сайта, на котором наиболее полное собрание сочинений. У меня это Литсовет. В дальнейшем я по результатам вычислений таблицы дополняю его, просматривая новые в остальных списках. Последовательность списка значения не имеет, можно даже отделять некоторые публикации, собирая в группы, и оставлять комментарии или заголовки. Так у меня отделены статьи от основной группы. Для слова "Статьи:" также работают правила поиска, но ни на одном сайте такого "произведения" нет и это никак не мешает мониторингу.
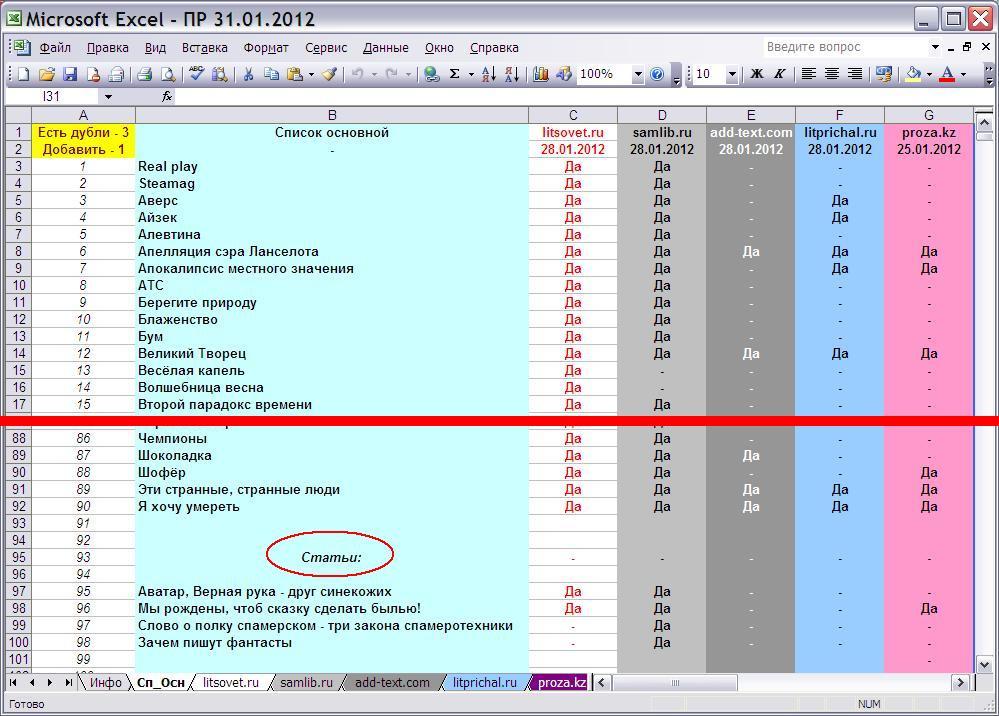
Важно - все глобальные преобразования основного списка, такие как сортировка, группировка и пр. так же лучше осуществлять во внешнем текстовом файле, чтобы это не повлияло на формулы и перекрёстные ссылки в Excel.
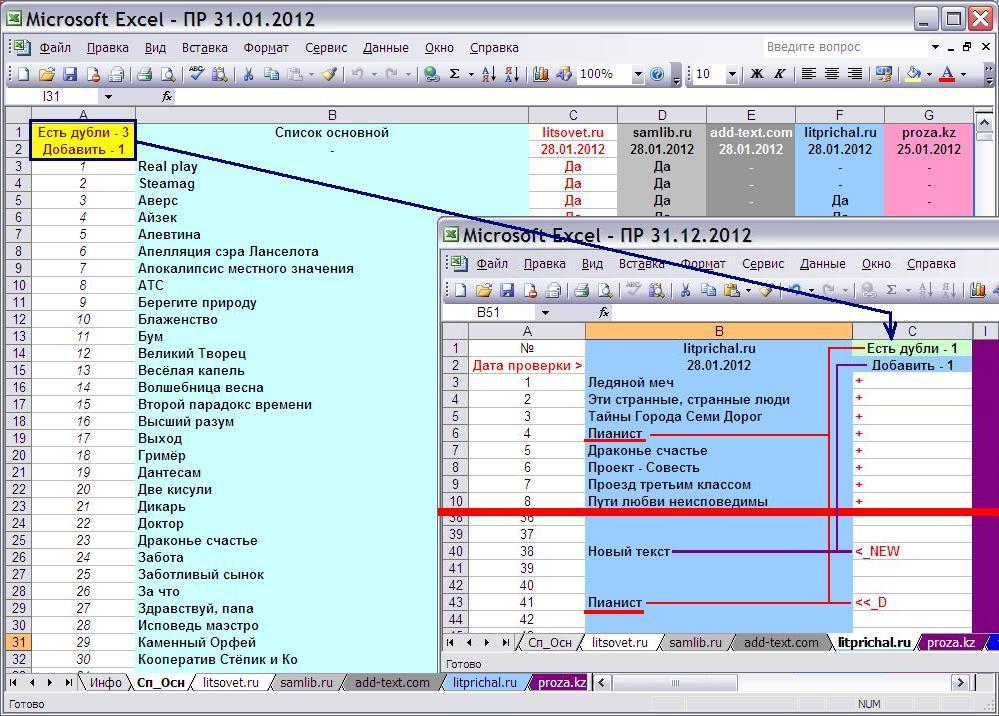
Обратите внимание на ячейки A1 и A2 в Сп_Осн, они информируют о наличии дублей (повторов) в списках произведений, и их количестве. Слово "Добавить" говорит о "новых" произведениях, не включенных в основной список, т.е. которые следует в него добавить. А "Есть дубли" информирует о повторах в "дочерних" списках. Отследить повторы и новинки в листах публикаций можно так же по ячейкам C1 и C2, которые, в отличие от Сп_Осн, уже указывают на их наличие в этом конкретном списке, а так же по всему столбцу C, в котором напротив интересующих нас произведений отображается <<_D и <_NEW. Дубли, помеченные <<_D , можно удалить, а новые добавить в основной список.
PS: Я не программист, потому не претендую на изящество и особою правильность воплощения этого файла - главное, он работает. Надеюсь, таблица принесёт вам пользу, а может полученный опыт работы с ней сподвигнет на самостоятельное освоение Excel и поможет в создании своих таблиц. Если заметите ошибки или недоработки, то буду рад замечаниям, советам и даже пожеланиям.
Особая благодарность создателям Excel и vdasus, за подсказки при редактировании версии 1.1 В планах реализовать функцию поиска по приближённому значению, и возможны иные доработки, необходимость в которых выявится во время эксплуатации.
Если будут пожелания, vdasus обещал написать свой вариант решения этой задачи, как её решал бы профессиональный программист (позже тут может появиться ссылка).
Если по каким-либо причинам ссылка не работает, то свежий файл можно скачать с сайта моего друга.
Скачать таблицу с vdasus.com
Если по каким-либо причинам ссылка не работает, то свежий файл можно скачать с сайта моего друга.
Скачать свежую таблицу
Ремарка от vdasus:
Если у кого-то английский Excel, то, достаточно скачать файл и открыть его. Английский Excel все формулы "переводит".
Синхронизация публикаций - в помощь сетератору. Работа со списками в Excel, Быстров В. С.
Первоисточник: wassillevs - http://vdasus.com